pandas.DataFrame 基于数据集#
本教程介绍如何使用 GluonTS 基于 pandas DataFrame 的数据集 PandasDataset。在介绍了一些常见用例后,我们将详细解释 PandasDataset 可以处理的数据格式、如何包含静态和动态特征以及如何进行训练/测试集拆分。
简介#
PandasDataset 旨在处理 pandas.DataFrame、pandas.Series 以及它们的任何集合。使用 GluonTS 的 dataframe 数据集开始建模的最低要求是,在 pandas.DataFrame 中包含一个具有固定频率的单调递增时间戳列表以及相应的目标值列表。
时间戳 |
目标 |
|---|---|
2021-01-01 00:00:00 |
-0.21 |
2021-01-01 01:00:00 |
-0.33 |
2021-01-01 02:00:00 |
-0.33 |
… |
… |
如果您有额外的动态或静态特征,可以将它们包含在单独的列中,如下所示
时间戳 |
目标 |
stat_cat_1 |
dyn_real_1 |
|---|---|---|---|
2021-01-01 00:00:00 |
-0.21 |
0 |
0.79 |
2021-01-01 01:00:00 |
-0.33 |
0 |
0.59 |
2021-01-01 02:00:00 |
-0.33 |
0 |
0.39 |
… |
… |
… |
… |
GluonTS 也支持多个时间序列。这些可以是上述格式的数据框列表(至少包含一个 timestamp 索引或列以及一个 target 列)、数据框字典,或者一个包含额外 item_id 列的长格式数据框,该列将不同的时间序列分组。当使用字典时,键被用作 item_id。包含静态和动态特征的两个时间序列示例如下:
时间戳 |
目标 |
item_id |
stat_cat_1 |
dyn_real_1 |
|---|---|---|---|---|
2021-01-01 00:00:00 |
-0.21 |
A |
0 |
0.79 |
2021-01-01 01:00:00 |
-0.33 |
A |
0 |
0.59 |
2021-01-01 02:00:00 |
-0.33 |
A |
0 |
0.39 |
2021-01-01 01:00:00 |
-1.24 |
B |
1 |
-0.60 |
2021-01-01 02:00:00 |
-1.37 |
B |
1 |
-0.91 |
在这里,时间序列值由 target 列表示,相应的 timestamp 值在 timestamp 列中。另一个必需的列是 item_id 列,它指示特定行属于哪个时间序列。在这个例子中,我们有两个时间序列,一个由项目 A 指示,另一个由 B 指示。此外,如果我们有其他特征,也可以包含进来(例如上面的 stat_cat_1 和 dyn_real_1)。
用例 1 - 从 长格式 数据框加载数据#
在第一个用例中,我们获得的数据是多个时间序列堆叠在一个数据框中,通过 item_id 列来区分不同的时间序列。
[1]:
import pandas as pd
url = (
"https://gist.githubusercontent.com/rsnirwan/a8b424085c9f44ef2598da74ce43e7a3"
"/raw/b6fdef21fe1f654787fa0493846c546b7f9c4df2/ts_long.csv"
)
df = pd.read_csv(url, index_col=0, parse_dates=True)
df.head()
[1]:
| 目标 | item_id | |
|---|---|---|
| 2021-01-01 00:00:00 | -1.3378 | A |
| 2021-01-01 01:00:00 | -1.6111 | A |
| 2021-01-01 02:00:00 | -1.9259 | A |
| 2021-01-01 03:00:00 | -1.9184 | A |
| 2021-01-01 04:00:00 | -1.9168 | A |
将数据读取到 pandas.DataFrame 后,我们可以轻松地将其转换为 gluonts.dataset.pandas.PandasDataset,然后训练估计器并获得预测结果。
[2]:
from gluonts.dataset.pandas import PandasDataset
ds = PandasDataset.from_long_dataframe(df, target="target", item_id="item_id")
[3]:
from gluonts.mx import DeepAREstimator, Trainer
estimator = DeepAREstimator(
freq=ds.freq, prediction_length=24, trainer=Trainer(epochs=1)
)
predictor = estimator.train(ds)
predictions = predictor.predict(ds)
100%|██████████| 50/50 [00:03<00:00, 14.52it/s, epoch=1/1, avg_epoch_loss=0.656]
用例 2 - 加载带缺失值的数据#
如果 timestamp 列不是等间隔且单调递增的,使用 PandasDataset 时会出错。这里我们展示如何填充缺失的间隙。
首先,让我们从 long 数据集中删除一些随机行。
[4]:
import pandas as pd
import numpy as np
url = (
"https://gist.githubusercontent.com/rsnirwan/a8b424085c9f44ef2598da74ce43e7a3"
"/raw/b6fdef21fe1f654787fa0493846c546b7f9c4df2/ts_long.csv"
)
df = pd.read_csv(url, index_col=0, parse_dates=True)
remove_ind = np.random.choice(np.arange(df.shape[0]), size=100, replace=False)
mask = [False if i in remove_ind else True for i in range(df.shape[0])]
df_missing_val = df.loc[mask, :] # dataframe with 100 rows removed from df
现在,我们按 item_id 分组,并对每个分组后的数据框重新索引。重新索引(如下所示)将在数据缺失的地方添加带有 NaN 值的新行。然后用户可以在每个数据框上使用 fillna() 方法来填充所需的值。
[5]:
from gluonts.dataset.pandas import PandasDataset
max_end = max(df.groupby("item_id").apply(lambda _df: _df.index[-1]))
dfs_dict = {}
for item_id, gdf in df_missing_val.groupby("item_id"):
new_index = pd.date_range(gdf.index[0], end=max_end, freq="1H")
dfs_dict[item_id] = gdf.reindex(new_index).drop("item_id", axis=1)
ds = PandasDataset(dfs_dict, target="target")
用例 3 - 从 宽格式 数据框加载数据#
在这里,数据是以 宽格式 给出的,其中时间序列在 DataFrame 中并排堆叠。我们可以简单地使用 dict 将其转换为 Series 对象的字典,并使用它构建 PandasDataset
[6]:
import pandas as pd
url_wide = (
"https://gist.githubusercontent.com/rsnirwan/c8c8654a98350fadd229b00167174ec4"
"/raw/a42101c7786d4bc7695228a0f2c8cea41340e18f/ts_wide.csv"
)
df_wide = pd.read_csv(url_wide, index_col=0, parse_dates=True)
print(df_wide.head())
A B C D E F G \
2021-01-01 00:00:00 -1.3378 0.1268 -0.3645 -1.0864 -2.3803 -0.2447 2.2647
2021-01-01 01:00:00 -1.6111 0.0926 -0.1364 -1.1613 -2.1421 -0.3477 2.4262
2021-01-01 02:00:00 -1.9259 -0.1420 0.1063 -1.0405 -2.1426 -0.3271 2.4434
2021-01-01 03:00:00 -1.9184 -0.4930 0.6269 -0.8531 -1.7060 -0.3088 2.4307
2021-01-01 04:00:00 -1.9168 -0.5057 0.9419 -0.7666 -1.4287 -0.4284 2.3258
H I J
2021-01-01 00:00:00 -0.7917 0.7071 1.3763
2021-01-01 01:00:00 -0.9609 0.6413 1.2750
2021-01-01 02:00:00 -0.9034 0.4323 0.6767
2021-01-01 03:00:00 -0.9602 0.3193 0.5150
2021-01-01 04:00:00 -1.2504 0.3660 0.1708
[7]:
from gluonts.dataset.pandas import PandasDataset
ds = PandasDataset(dict(df_wide))
如 用例 1 所示,我们现在可以使用 ds 来训练估计器。
通用用例#
在这里,我们将详细解释 PandasDataset 可以处理的数据格式、如何包含静态和动态特征以及如何进行训练/测试集拆分。
虚拟数据生成#
让我们创建一个函数,该函数生成符合上述要求(timestamp 索引和 target 列)的虚拟时间序列。该函数随机采样正弦/余弦曲线并输出它们的和。您无需理解其工作原理。我们只需使用以固定频率单调递增的日期时间值调用 generate_single_ts,即可获得一个包含 timestamp 和 target 值的 pandas.DataFrame。
[8]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def generate_single_ts(date_range, item_id=None) -> pd.DataFrame:
"""create sum of `n_f` sin/cos curves with random scale and phase."""
n_f = 2
period = np.array([24 / (i + 1) for i in range(n_f)]).reshape(1, n_f)
scale = np.random.normal(1, 0.3, size=(1, n_f))
phase = 2 * np.pi * np.random.uniform(size=(1, n_f))
periodic_f = lambda x: scale * np.sin(np.pi * x / period + phase)
t = np.arange(0, len(date_range)).reshape(-1, 1)
target = periodic_f(t).sum(axis=1) + np.random.normal(0, 0.1, size=len(t))
ts = pd.DataFrame({"target": target}, index=date_range)
if item_id is not None:
ts["item_id"] = item_id
return ts
[9]:
prediction_length, freq = 24, "1H"
T = 10 * prediction_length
date_range = pd.date_range("2021-01-01", periods=T, freq=freq)
ts = generate_single_ts(date_range)
print("ts.shape:", ts.shape)
print(ts.head())
ts.loc[:, "target"].plot(figsize=(10, 5))
ts.shape: (240, 1)
target
2021-01-01 00:00:00 -1.175310
2021-01-01 01:00:00 -1.152185
2021-01-01 02:00:00 -1.216568
2021-01-01 03:00:00 -1.150387
2021-01-01 04:00:00 -1.247621
[9]:
<Axes: >
使用单个时间序列进行训练#
现在,我们使用生成的时间序列创建一个 GluonTS 数据集并训练模型。由于我们将多次使用训练/评估循环,因此创建一个函数。该函数的输入是多种格式的时间序列和一个估计器。输出是 MSE (均方误差)。在此函数中,我们训练估计器以获得预测器,使用预测器创建预测结果并返回一个度量指标。我们还创建了一个 DeepAREstimator。请注意,我们只运行了 1 个 epoch 的训练。通常需要更多的 epoch 才能完全训练模型。
[10]:
from gluonts.mx import DeepAREstimator, Trainer
from gluonts.evaluation import make_evaluation_predictions, Evaluator
def train_and_predict(dataset, estimator):
predictor = estimator.train(dataset)
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset, predictor=predictor
)
evaluator = Evaluator(quantiles=(np.arange(20) / 20.0)[1:])
agg_metrics, item_metrics = evaluator(ts_it, forecast_it, num_series=len(dataset))
return agg_metrics["MSE"]
estimator = DeepAREstimator(
freq=freq, prediction_length=prediction_length, trainer=Trainer(epochs=1)
)
现在可以将 ts 数据框转换为 GluonTS 数据集并训练模型了。为此,我们导入 PandasDataset 并使用我们的时间序列 ts 创建一个实例。如果 target 列名为 "target",则实际上无需将其提供给构造函数。此外,如果时间戳是时间或周期范围,则 freq 会从数据中推断出来。但是,在本教程中,我们将具体说明如何通用地使用这些参数。
[11]:
from gluonts.dataset.pandas import PandasDataset
ds = PandasDataset(ts, target="target", freq=freq)
train_and_predict(ds, estimator)
100%|██████████| 50/50 [00:03<00:00, 15.02it/s, epoch=1/1, avg_epoch_loss=0.539]
Running evaluation: 100%|██████████| 1/1 [00:00<00:00, 5.04it/s]
[11]:
0.023472231979132386
使用多个时间序列进行训练#
如上所述,我们还可以使用单个时间序列数据框的列表。甚至可以使用数据框字典或包含多个时间序列的单个长格式数据框,下文将对此进行说明。因此,让我们创建多个时间序列并使用它们来训练模型。
[12]:
N = 10
multiple_ts = [generate_single_ts(date_range) for i in range(N)]
ds = PandasDataset(multiple_ts, target="target", freq=freq)
train_and_predict(ds, estimator)
100%|██████████| 50/50 [00:03<00:00, 15.26it/s, epoch=1/1, avg_epoch_loss=0.91]
Running evaluation: 100%|██████████| 10/10 [00:00<00:00, 36.63it/s]
[12]:
0.046774466353901624
如果数据集是以长格式数据框的形式给出,我们还可以使用另一个构造函数 from_long_dataframe。请注意,在这种情况下,我们还需要提供 item_id。
[13]:
ts_in_long_format = pd.concat(
[generate_single_ts(date_range, item_id=i) for i in range(N)]
)
# Note we need an item_id column now and provide its name to the constructor.
# Otherwise, there is no way to distinguish different time series.
ds = PandasDataset.from_long_dataframe(
ts_in_long_format, item_id="item_id", target="target", freq=freq
)
train_and_predict(ds, estimator)
100%|██████████| 50/50 [00:03<00:00, 14.88it/s, epoch=1/1, avg_epoch_loss=0.742]
Running evaluation: 100%|██████████| 10/10 [00:00<00:00, 36.01it/s]
[13]:
0.09143225550221631
包含静态和动态特征#
PandasDataset 还允许我们包含时间序列的特征。文档中列出了所有可用特征。这里,我们使用动态实数值特征和静态分类特征。为了模拟这些特征,我们将简单地包装我们精心制作的数据生成器 generate_single_ts,并添加一个静态分类特征和两个动态实数值特征。
[14]:
def generate_single_ts_with_features(date_range, item_id) -> pd.DataFrame:
ts = generate_single_ts(date_range, item_id)
T = ts.shape[0]
# static features are constant for each series
ts["dynamic_real_1"] = np.random.normal(size=T)
ts["dynamic_real_2"] = np.random.normal(size=T)
# ... we can have as many static or dynamic features as we like
return ts
ts = generate_single_ts_with_features(date_range, item_id=0)
ts.head()
[14]:
| 目标 | item_id | dynamic_real_1 | dynamic_real_2 | |
|---|---|---|---|---|
| 2021-01-01 00:00:00 | -0.822858 | 0 | 0.212849 | -0.313528 |
| 2021-01-01 01:00:00 | -0.932843 | 0 | -0.347438 | 0.690760 |
| 2021-01-01 02:00:00 | -1.415959 | 0 | -0.498104 | -1.432175 |
| 2021-01-01 03:00:00 | -1.471930 | 0 | 0.499352 | 0.426574 |
| 2021-01-01 04:00:00 | -1.196347 | 0 | 0.242846 | 0.378769 |
现在,当我们创建 GluonTS 数据集时,需要告知构造函数哪些列是分类特征和实数值特征。此外,我们还需要对 estimator 进行细微修改。我们还需要让 estimator 知道有更多的特征输入。请注意,如果提供了分类特征,DeepAR 也需要基数作为输入。我们有一个静态分类特征,可以取两个值(0 或 1)。在这种情况下,基数是一个包含一个元素的列表 [2,]。
[15]:
estimator_with_features = DeepAREstimator(
freq=ds.freq,
prediction_length=prediction_length,
use_feat_dynamic_real=True,
use_feat_static_real=True,
use_feat_static_cat=True,
cardinality=[
3,
],
trainer=Trainer(epochs=1),
)
现在让我们生成多个时间序列,既作为数据框字典,也作为单个长格式数据框。我们还生成了一个专门的静态特征数据框。请注意,我们没有提供 freq 和 timestamp,因为它们是从时间索引自动推断出来的。我们也没有传递 target 参数,因为其默认值为 "target",这是我们数据框中的目标列。
[16]:
multiple_ts = {
i: generate_single_ts_with_features(date_range, item_id=i) for i in range(N)
}
static_features = pd.DataFrame(
{
"color": pd.Categorical(np.random.choice(["red", "green", "blue"], size=N)),
"height": np.random.normal(loc=100, scale=15, size=N),
},
index=list(multiple_ts.keys()),
)
multiple_ts_long = pd.concat(multiple_ts.values())
multiple_ts_dataset = PandasDataset(
multiple_ts,
feat_dynamic_real=["dynamic_real_1", "dynamic_real_2"],
static_features=static_features,
)
# for long-dataset we use a different constructor and need a `item_id` column
multiple_ts_long_dataset = PandasDataset.from_long_dataframe(
multiple_ts_long,
item_id="item_id",
feat_dynamic_real=["dynamic_real_1", "dynamic_real_2"],
static_features=static_features,
)
就是这样!现在我们可以使用所有数据集调用 train_and_predict。
[17]:
train_and_predict(multiple_ts_dataset, estimator_with_features)
100%|██████████| 50/50 [00:04<00:00, 12.07it/s, epoch=1/1, avg_epoch_loss=1.4]
Running evaluation: 100%|██████████| 10/10 [00:00<00:00, 37.14it/s]
[17]:
0.25145185006648246
[18]:
train_and_predict(multiple_ts_long_dataset, estimator_with_features)
100%|██████████| 50/50 [00:04<00:00, 12.19it/s, epoch=1/1, avg_epoch_loss=1.48]
Running evaluation: 100%|██████████| 10/10 [00:00<00:00, 37.20it/s]
[18]:
0.3680281639680776
使用训练/测试集拆分#
在这里,我们将数据框/数据框组拆分为训练数据和测试数据。然后可以使用训练数据来训练模型,使用测试数据进行预测。对于训练,我们将使用整个数据集直至最后的 prediction_length 条目。对于测试,我们将整个数据集馈送到 make_evaluation_predictions 中,它会自动为我们拆分最后的 prediction_length 条目并返回它们的预测结果。然后,我们将这些预测结果转发给 Evaluator,它会为我们计算一系列指标(包括 MSE、RMSE、MAPE、sMAPE 等)。
[19]:
train = PandasDataset(
{item_id: df[:-prediction_length] for item_id, df in multiple_ts.items()},
feat_dynamic_real=["dynamic_real_1", "dynamic_real_2"],
static_features=static_features,
)
test = PandasDataset(
multiple_ts,
feat_dynamic_real=["dynamic_real_1", "dynamic_real_2"],
static_features=static_features,
)
[20]:
predictor = estimator_with_features.train(train)
forecast_it, ts_it = make_evaluation_predictions(dataset=test, predictor=predictor)
evaluator = Evaluator(quantiles=(np.arange(20) / 20.0)[1:])
agg_metrics, item_metrics = evaluator(ts_it, forecast_it, num_series=len(test))
100%|██████████| 50/50 [00:04<00:00, 11.58it/s, epoch=1/1, avg_epoch_loss=1.28]
Running evaluation: 100%|██████████| 10/10 [00:00<00:00, 36.55it/s]
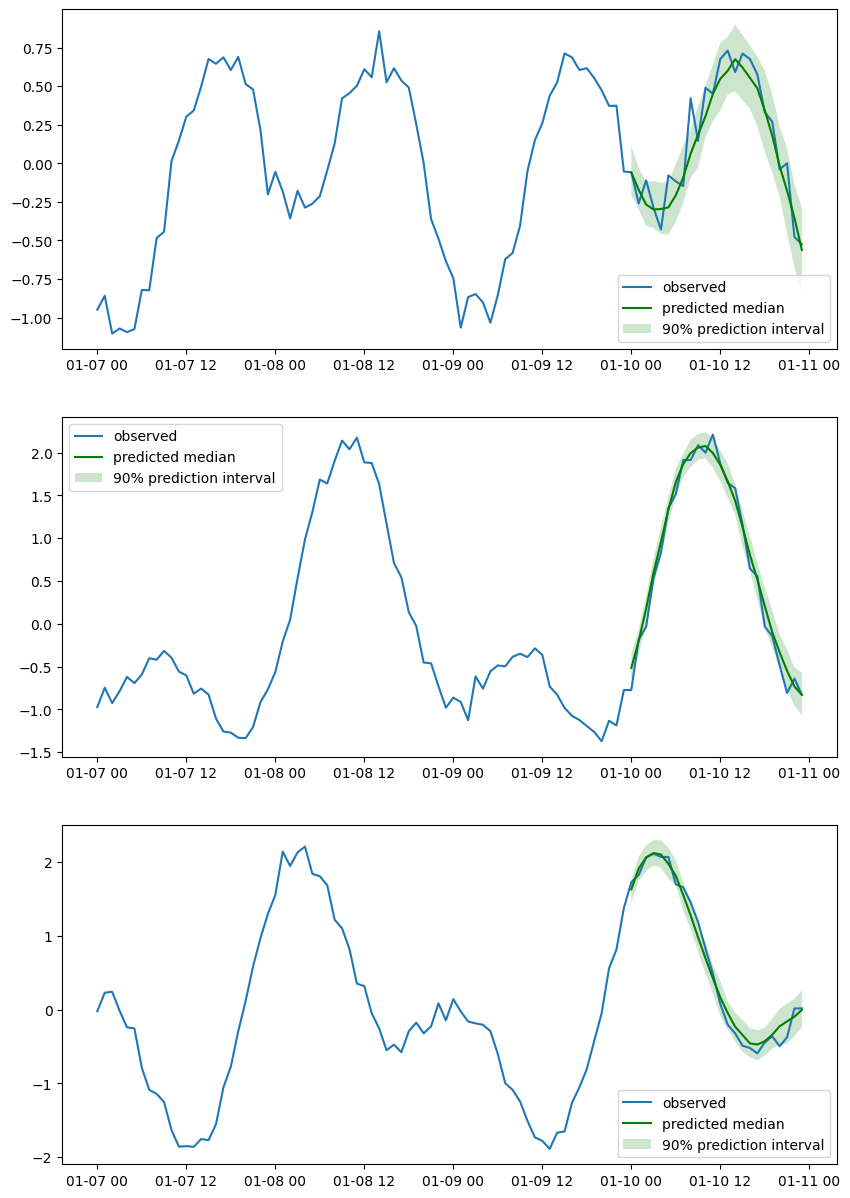
训练并可视化预测结果#
让我们生成 100 个时间序列数据框,创建一个训练/测试集拆分,训练一个估计器,并可视化预测结果。
[21]:
prediction_length, freq = 24, "1H"
T = 10 * prediction_length
date_range = pd.date_range("2021-01-01", periods=T, freq=freq)
N = 100
time_seriess = [generate_single_ts(date_range, item_id=i) for i in range(N)]
train = PandasDataset([ts.iloc[:-prediction_length, :] for ts in time_seriess])
test = PandasDataset(time_seriess)
[22]:
estimator = DeepAREstimator(
freq=freq,
prediction_length=prediction_length,
trainer=Trainer(epochs=10),
)
predictor = estimator.train(train)
forecast_it, ts_it = make_evaluation_predictions(dataset=test, predictor=predictor)
forecasts = list(forecast_it)
tests = list(ts_it)
evaluator = Evaluator(quantiles=(np.arange(20) / 20.0)[1:])
agg_metrics, item_metrics = evaluator(tests, forecasts, num_series=len(test))
100%|██████████| 50/50 [00:03<00:00, 14.84it/s, epoch=1/10, avg_epoch_loss=0.621]
100%|██████████| 50/50 [00:03<00:00, 15.42it/s, epoch=2/10, avg_epoch_loss=-0.309]
100%|██████████| 50/50 [00:03<00:00, 15.52it/s, epoch=3/10, avg_epoch_loss=-0.417]
100%|██████████| 50/50 [00:03<00:00, 14.90it/s, epoch=4/10, avg_epoch_loss=-0.475]
100%|██████████| 50/50 [00:03<00:00, 15.25it/s, epoch=5/10, avg_epoch_loss=-0.503]
100%|██████████| 50/50 [00:03<00:00, 15.48it/s, epoch=6/10, avg_epoch_loss=-0.532]
100%|██████████| 50/50 [00:03<00:00, 15.48it/s, epoch=7/10, avg_epoch_loss=-0.558]
100%|██████████| 50/50 [00:03<00:00, 15.34it/s, epoch=8/10, avg_epoch_loss=-0.57]
100%|██████████| 50/50 [00:03<00:00, 15.34it/s, epoch=9/10, avg_epoch_loss=-0.591]
100%|██████████| 50/50 [00:03<00:00, 15.70it/s, epoch=10/10, avg_epoch_loss=-0.592]
Running evaluation: 100%|██████████| 100/100 [00:00<00:00, 1964.53it/s]
让我们绘制几个随机选定的时间序列。
[23]:
n_plot = 3
indices = np.random.choice(np.arange(0, N), size=n_plot, replace=False)
fig, axes = plt.subplots(n_plot, 1, figsize=(10, n_plot * 5))
for index, ax in zip(indices, axes):
ax.plot(tests[index][-4 * prediction_length :].to_timestamp())
plt.sca(ax)
forecasts[index].plot(intervals=(0.9,), color="g")
plt.legend(["observed", "predicted median", "90% prediction interval"])